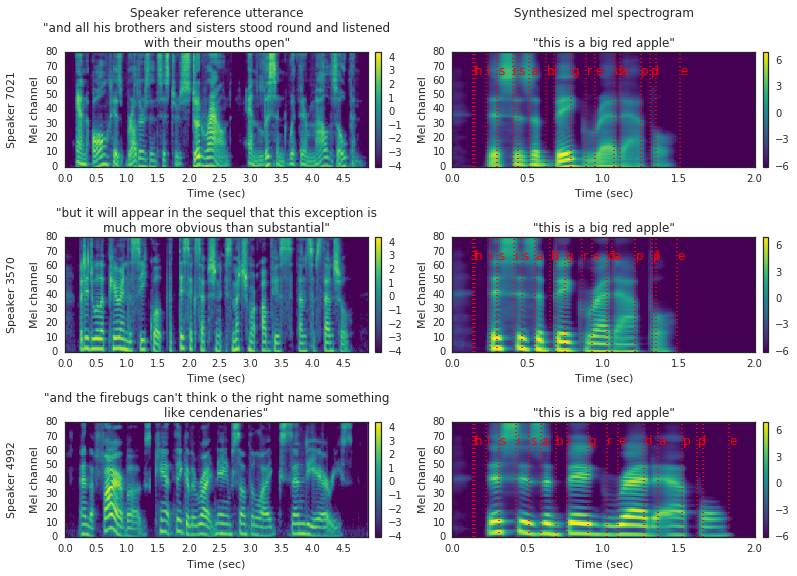
Source: Audio samples from “Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis”
Your email address will not be published. Required fields are marked *
Comment *
Name *
Email *
Website
Save my name, email, and website in this browser for the next time I comment.
Δ
This site uses Akismet to reduce spam. Learn how your comment data is processed.